RAFT Adapting Language Model to Domain Specific RAG

RAFT一種在資訊檢索領域微調大型語言模型的方法。
RAFT Method
背景
大型語言模型(LLMs)在特定場景中,對一般知識推理的重要性相對較低,如何提升精確度(Accuracy)才是關鍵目標。尤其是在特定領域中,如何有效整合檢索器與生成器,儼然成為本任務重中之重的挑戰。基於此,本文將探索如何讓 LLM 能更高效地利用領��域知識,進而提升性能。
研究核心目標
本文以提升 LLMs 在特定領域的適應性與準確性為核心目標,特別是在回答基於特定文檔的問題時,結合檢索結果與模型調適,以克服以下兩大挑戰:
- 有限的領域學習機會:LLMs 缺乏掌握特定全局知識的能力,無法有效利用檢索到的文檔來構建深層的回答。
- 檢索信息的干擾性:實際應用中,檢索到的文件可能包含無關或錯誤資訊,導致模型生成的答案受到影響。
此外,傳統的監督微調(Supervised Fine-Tuning,SFT)方法或 RAG(Retrieval-Augmented Generation)設置雖然提供部分解決的方案,但仍存在一些局限性:
- 忽略檢索結果的不完美性:大多數方法假設檢索到的文檔是高度相關的,忽略了實際應用中檢索錯誤的可能性,導致模型對干擾文檔的抵抗力不足。
- 未充分利用檢索過程中的學習機會:在微調階段未引入檢索結果,導致模型在推理時對上下文文件的使用效率不佳。
研究方法
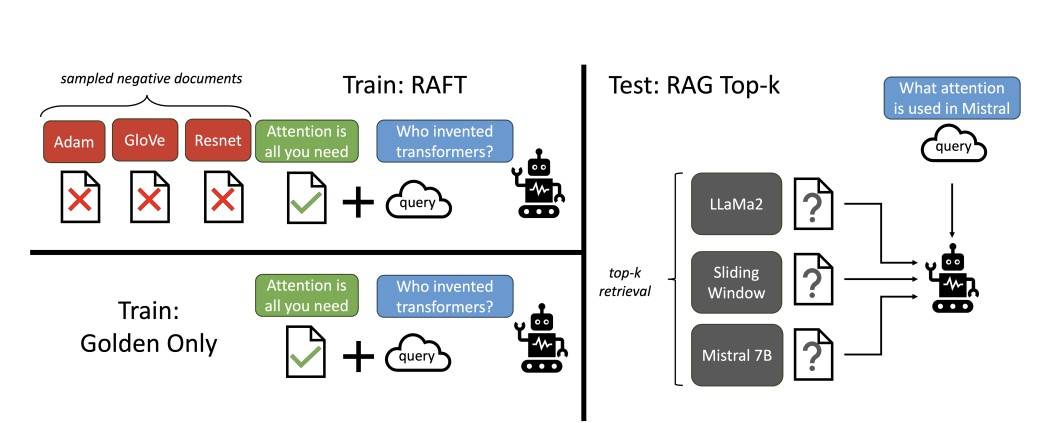
為解決上述挑戰,本文提出一種結合指令式調整與 RAG 模型的新方法,稱為 檢索增強微調(Retrieval-Augmented Fine-Tuning, RAFT)。RAFT 旨在讓模型不僅能學習特定領域的知識,還能提升其在面對檢索結果不完美情況下的穩定性。研究的核心設計如下:
- 多樣化訓練樣本設置:透過調整訓練數據中「黃金文件」(即與答案高度相關的文檔)與干擾文檔的比例,讓訓練模型更好地平衡相關信息與無關信息之間的判斷力。
- 鏈式推理答案生成(Chain-of-Thought, CoT):針對每個問題,生成帶有推理過程的答案,幫助模型學會在答案中體現思維邏輯,而非僅僅記憶結果。
- 引入干擾文檔:在訓練階段混合黃金文檔與干擾文檔,使模型學習如何辨別正確信息,以增強應對現實情況的能力。
RAFT 的訓練數據設置包含以下兩種類型,這種混合策略能在提升模型領域知識的同時,增強模型對檢索到不相關結果時的容錯能力:
- P% 的樣本:包含問題(Q)、黃金文件(D*)及干擾文件(D1, D2, …, Dk),目標生成答案(A*)。
- (1−P)% 的樣本:移除黃金文件,僅包含問題與干擾文件,目的是讓模型在缺少相關文檔時仍能生成正確答案。
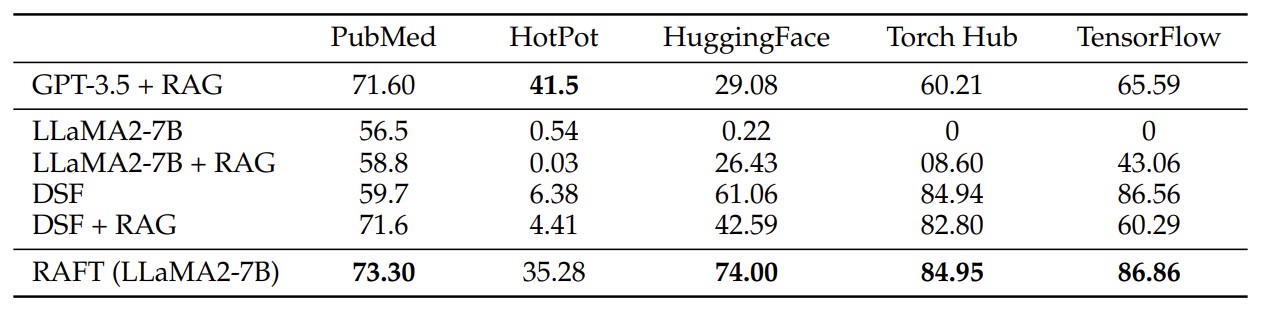
基準模型與比較方法
為評估 RAFT 方法的有效性,本文設計以下基準模型進行對比:
- LlaMA2–7B-chat + 0-shot:以指令微調模型,但僅根據問題生成答案,不包含參考文件。
- LlaMA2–7B-chat + RAG:結合檢索結果的生成模型,但未進行領域特定微調。
- 領域特定微調 + 0-shot 提示(DSF):透過監督微調學習領域知識,但不考慮上下文文件。
- 領域特定微調 + RAG(DSF + RAG):對 DSF 模型加入檢索支持,測試其在不熟悉知識時的表現。
關鍵研究問題與發現
-
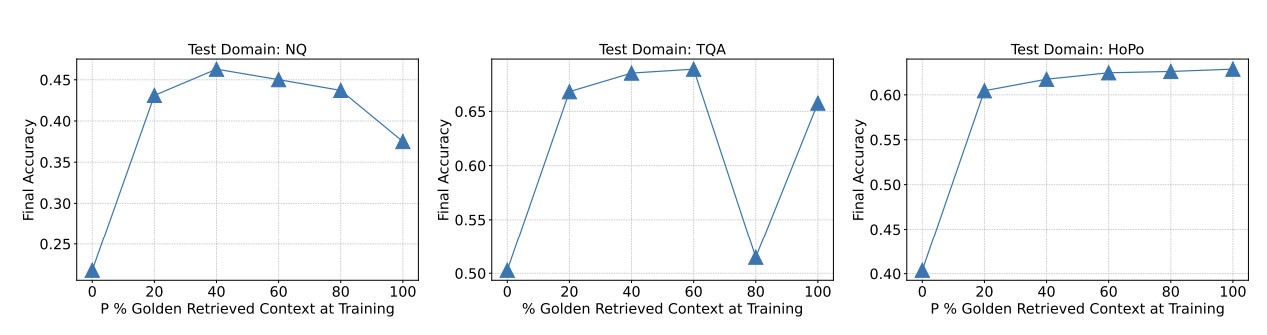
Q1:訓練時是否始終需要黃金上下文? A1:傳統觀點認為,訓練數據應始終包含黃金文件(P=100%),以最大化模型利用上下文的能力。然而,本研究表明:當黃金文件比例為 P=80% 時,模型在 RAG 任務上的性能反而有所提升。這表明適當比例的干擾文件可以幫助模型學習更具判斷力的內容篩選能力,減少對理想狀態的依賴。
-
Q2:CoT 答案對性能的提升? A2:引入 CoT,不僅提升了模型的準確率,還能避免簡單答案導致的過度擬合問題。該方法特別適用於需要深入推理的問題場景,顯著增強了模型的泛化能力。

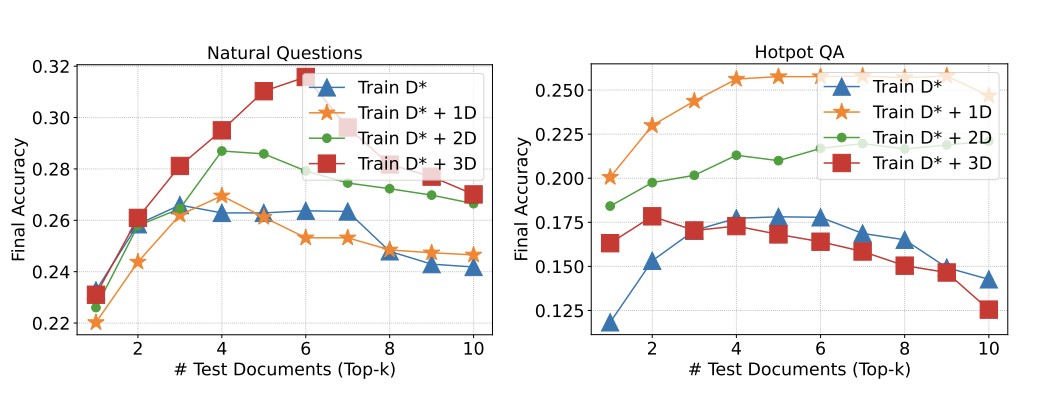
- Q3:干擾文檔數量對模型性能的影響? A3:本文進一步研究了在測試階段加入不同數量干擾文檔時,模型的穩健性如何受到影響。結果顯示,RAFT 模型對於無關信息的耐受性顯著優於基準模型,這得益於訓練中混合金標與干擾文檔的策略。
結論
本文提出的 RAFT 方法,通過混合黃金上下文與干擾文檔,為 LLM 提供了一種在領域特定任務中提升準確性與穩健性的有效途徑。相較於傳統的監督微調和 RAG 方法,RAFT 的創新點包括:
- 平衡相關與無關文檔的信息權重,提升模型在現實檢索場景中的耐受性。
- 引入鏈式推理答案生成,幫助模型學會深層次邏輯推導,避免過度擬合。
- 適度調整訓練數據的黃金文件比例,證明 100% 金標並非最佳選擇。